Very similar to an array, a linked list is a data structure that represents a collection of items. While on the surface, they are identical there are big differences under the hood.
Memory inside of a computer can be visualized as a giant excel spread sheet. When you store an array, your code finds a contiguous group of empty cells in memory and assigns them to store data.
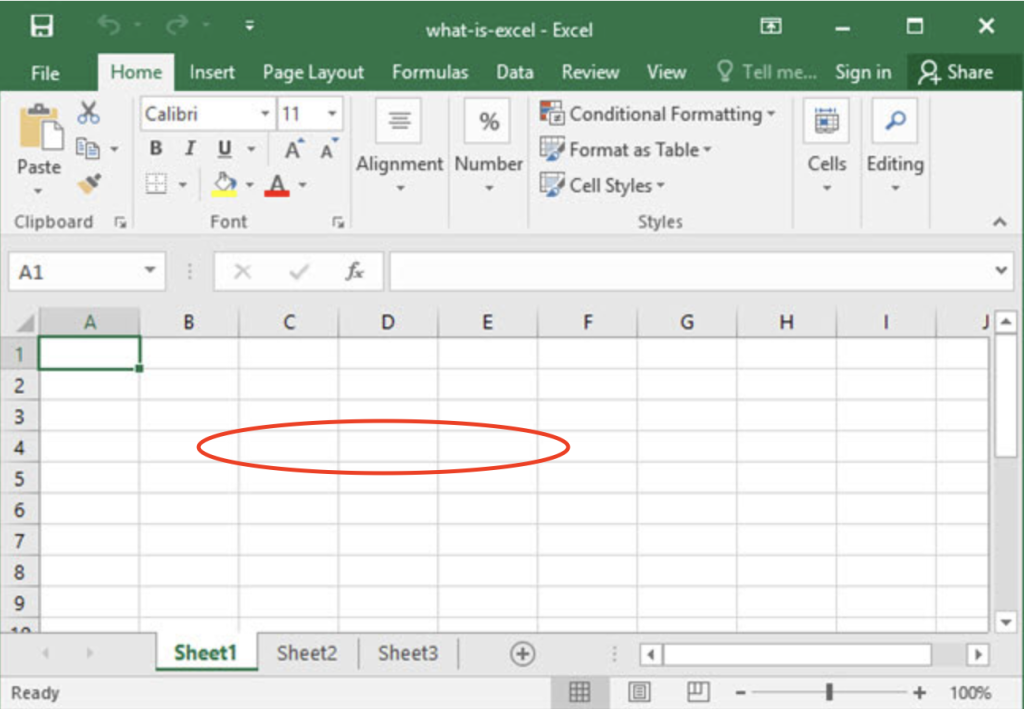
This is why arrays are good at “indexing”. If we know the place in memory where an array is stored, we can quickly access values with a number (example: arr[0]). This is because your program knows the exact place in memory.
Linked-list work way different. Instead of the values being place next to each other in memory, they are stored all over.
Connected data that is dispersed throughout memory are known as nodes. In a linked list, each node represents one item.
The big question is: If nodes are not next to each other in memory, how does the computer know where the memory places are?
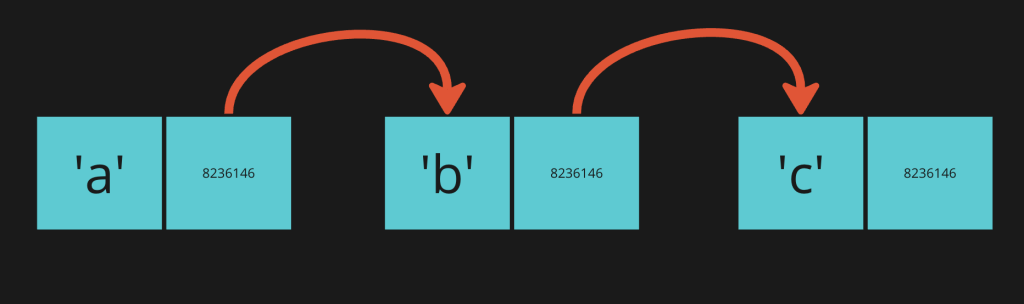
The key to understanding a linked list is each node also comes with a little extra information, namely, the memory address of the next node in the list.
This extra piece of information is a link to the next chain in the linked list, sometimes referred to as a pointer, that points to the next place in memory.
A linked list first node is referred to as a head, and the final node is the tail. The tail is identified because the last node is null. All any algorithm needs is the head in order to traverse because we can iterate until we reach null.
Linked List C# Implementation
C# already has a linked list built-in already, so there is no real need to create one on your own IRL.
But given that top-tier companies will expect you to have incredible skills with linked-list, it is crucial to practice building them.
Let’s create our own linked list with C#:
public class Node
{
// Properties to store data and the reference to the next node
public string Data { get; set; }
public Node NextNode { get; set; }
// Constructor to initialize the data
public Node(string data)
{
this.Data = data;
this.NextNode = null;
}
}The node class is one “chunk” in our chain. It has two attributes: Data contains the node’s primary value (example: “a”).
The NextNode is the “link in the chain” and points to the next node.
Node node1 = new Node("once");
Node node2 = new Node("upon");
Node node3 = new Node("a");
Node node4 = new Node("time");
node1.NextNode = node2; //Attach node1 to node2
node2.NextNode = node3; //Attach node2 to node3
node3.NextNode = node4; //Attach node3 to node3Using the code above, we first create our nodes and attach the “link” together via NextNode.
public class LinkedList
{
private Node _head { get; set; }
public LinkedList(Node head)
{
_head = head;
}
}Read A Linked List
A computer can read from an array in O(1) time, but what about a linked list? Let’s figure our how we can traverse a linked list to get values.
If you want to read values in a linked list, the computer cannot look it up in one step. Since the memory is spread all through out the memory, it’s more difficult to find. Each node could literally be anywhere in memory.
To read values, the computer must go through an iterative process. First, it access the first node, then follows the link to the next node. After that the next node, and so on and so on.
To get any node we want, we first start at the head and follow the chain of nodes until we reach the end.
public string Read(int index)
{
Node currentNode = _head;
int currentIndex = 0;
while (currentIndex < index)
{
if (currentNode == null)
{
return null;
}
currentNode = currentNode.NextNode;
currentIndex++;
}
return currentNode?.Data;
}First, we create a variable called currentNode that refers to the node we’re current accessing. Since we always start at the beginning, we’re going to access the head node.
currentnNode = _head;Next, we create an index so that we know when to stop at the desired index.
current_index = 0;We then loop thru, while the current index is less than the index we’re attempting to read:
while(currentIndex < index)Next, we use the NextNode property to “traverse” the list. Each time we iterate and access the list, we are moving to the next node.
currentNode = currentNode.NextNode;Finally, increase the currentIndex to keep track of our state.
Search A Linked List in C#
Searching is a very similar action to reading except that we are just finding the index.
Linked lists also have a search speed of O(n). To search for a value, we need to traverse thru the list just like a read.
public int? IndexOf(string value)
{
Node currentNode = _head;
int currentIndex = 0;
while (currentNode != null)
{
if (currentNode.Data == value)
{
return currentIndex;
}
currentNode = currentNode.NextNode;
currentIndex++;
}
return null;
}As you can see, a search is very similar to read, but does stop at a particular index. It just runs until we wither find the value or reach the end of the list.
Insertion Into A Linked List in C#
Linked list have not made a good impression on us thus far. They’re no better than arrays at search and much worse at reading. But insertion is one operation which linked list have a distinct advantage.
Worst-case scenarios for insertion into an array is inserting at the start. With linked-list, insertion at the beginning of the list takes just one step–which is O(1).
Consider we have the existing linked list:
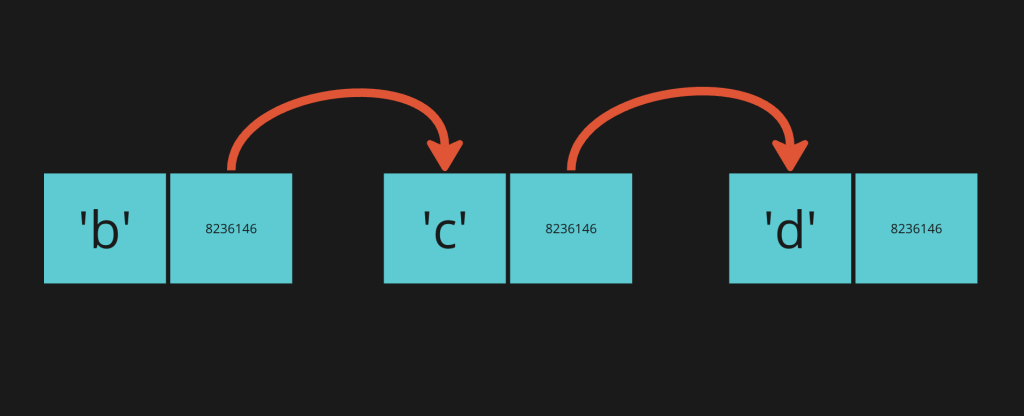
If we want to add the correct letter “a” to this list, we need to create a new node and link it to the “b” node.
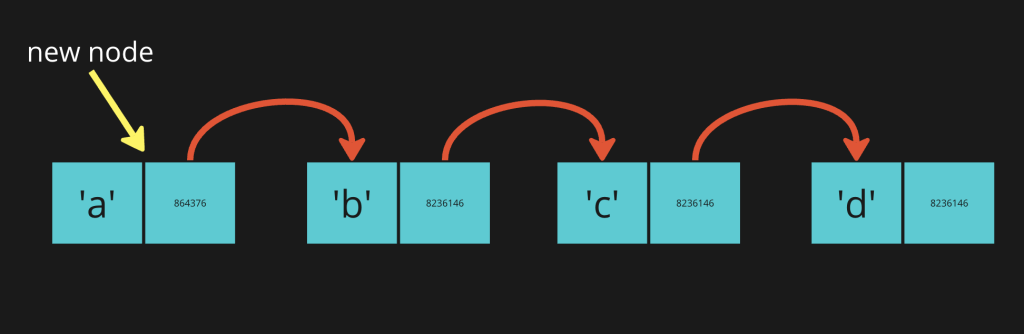
Let’s say we also want to add an extra “a” between “b” and “c”. (because why not right? lol)
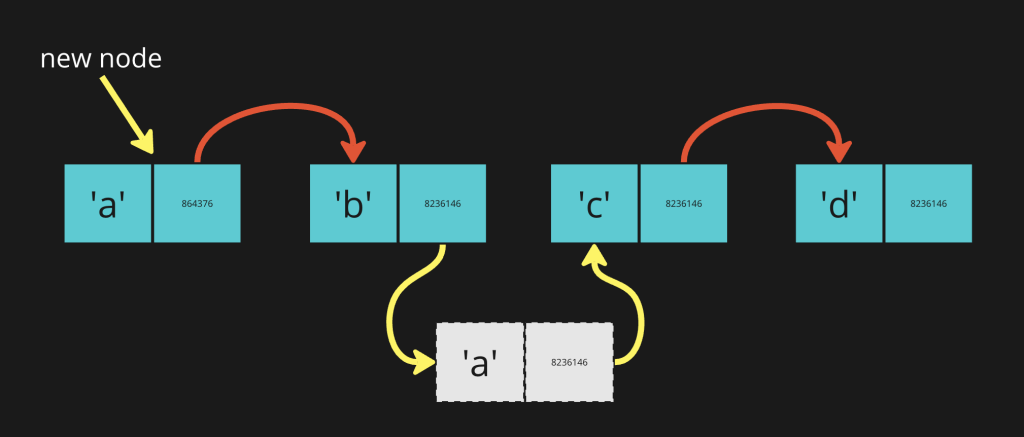
In order to accomplish an insertion we to iterate to the node previous where we plan to insert, so that we can point to the newly created node.
It is very easy to spot the actual insert process because it looks like this:
newNode.NextNode = _current.NextNode; // point new node to the node after
_current.NextNode = newNode; // point // point the previous node to the new nodeLet’s add an insertion method to our linked:
public void InsertAtIndex(int index, string value)
{
Node newNode = new Node(value);
if (index == 0)
{
newNode.NextNode = FirstNode;
FirstNode = newNode;
return;
}
Node currentNode = FirstNode;
int currentIndex = 0;
while (currentIndex < index - 1 && currentNode != null)
{
currentNode = currentNode.NextNode;
currentIndex++;
}
if (currentNode == null)
{
Console.WriteLine("Index out of bounds");
return;
}
newNode.NextNode = currentNode.NextNode;
currentNode.NextNode = newNode;
}To use this method, we pass in both the new value and the index where we want to insert.
First, we create a new node with the value provided to our method:
Node newNode = new Node(value);Next, we must handle the specific case where we’re inserting into at the head of the linked list.
if (index == 0)
{
newNode.NextNode = FirstNode;
FirstNode = newNode;
return;
}The code after deals with inserting at another point in the list. Similar to reading and searching we start off by grabbing the first node in the list:
Node currentNode = FirstNode;
int currentIndex = 0;We then use a while loop to traverse the list just before the spot we plan on inserting the node.
while (currentNode != null)
{
if (currentNode.Data == value)
{
return currentIndex;
}
currentNode = currentNode.NextNode;
currentIndex++;
}Finally, we can actually insert the node!
newNode.NextNode = currentNode.NextNode;
currentNode.NextNode = newNode;Linked List Deletion in C#
Linked lists are also useful when it comes to deleting from the beginning of a list.
When deleting a node from the beginning of a linked list, all we need to do is change the FirstNode of the linked list to now point to the second node.
While deleting from the beginning or end of a linked list is straight forward, deleting from anywhere is slightly more involved.
Let’s say we want to delete the value at index 2 (this is “a” in our case).
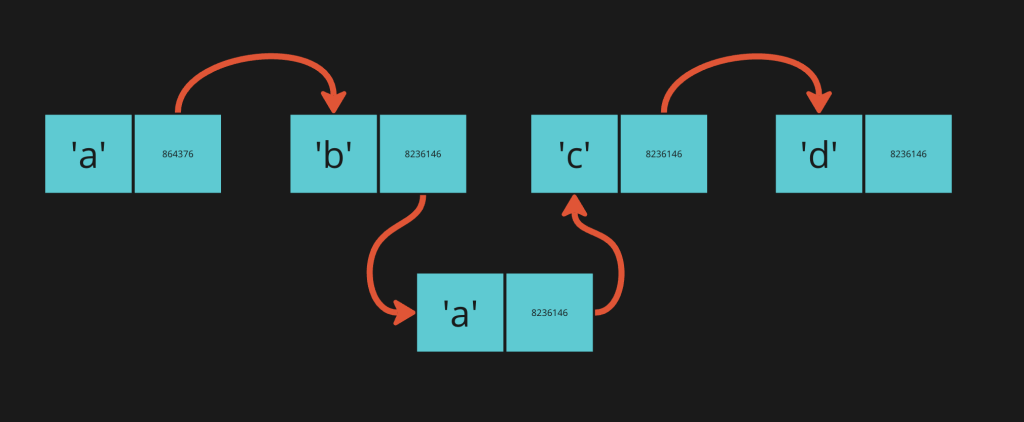
To make this happen, we need to get the node right before the “a”. This is very similar to what we did to insert.
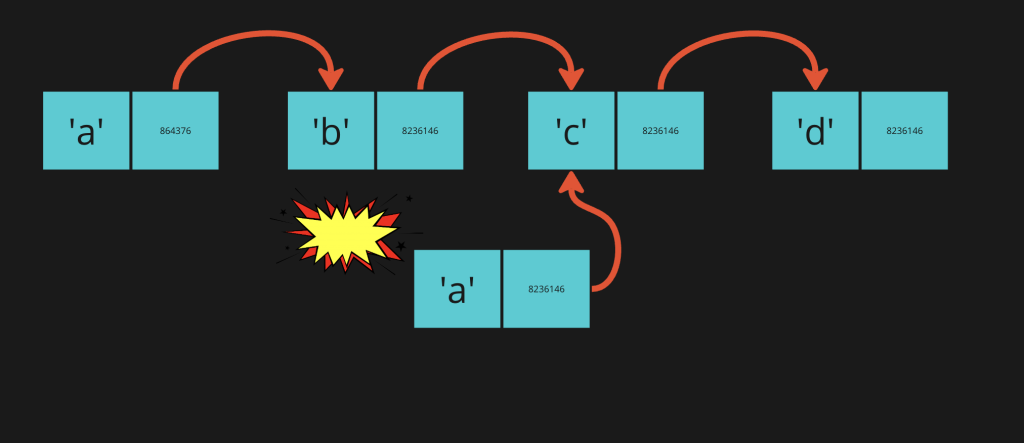
This may seem like an odd thing to do and you may be thinking “but… the node exists”. It does still exist in memory somewhere but the path has been severed. No longer being connected to the other nodes will trigger garbage collector for removal.
public void DeleteAtIndex(int index)
{
// If we are deleting the first node
if (index == 0)
{
// Simply set the first node to be what is currently the second node
FirstNode = FirstNode.NextNode;
return;
}
Node currentNode = FirstNode;
int currentIndex = 0;
// First, we find the node immediately before the one we want to delete and call it currentNode
while (currentIndex < index - 1 && currentNode.NextNode != null)
{
currentNode = currentNode.NextNode;
currentIndex++;
}
if (currentNode.NextNode == null)
{
Console.WriteLine("Index out of bounds");
return;
}
// We find the node that comes after the one we're deleting
Node nodeAfterDeletedNode = currentNode.NextNode.NextNode;
// We change the link of the currentNode to point to the nodeAfterDeletedNode,
// leaving the node we want to delete out of the list
currentNode.NextNode = nodeAfterDeletedNode;
}The first part of the method deals with the specific case we are deleting the first node.
if (index == 0)
{
// Simply set the first node to be what is currently the second node
FirstNode = FirstNode.NextNode;
return;
}
All we are doing is changing the FirstNode to be the second and we are done.
Conclusion
In summary, linked lists excel in dynamic data management with efficient insertion and deletion operations, making them a versatile choice for various programming applications despite their inherent trade-offs.