Imagine that you are coding a program that allows customers to order vapes online. You are tasked with making a menu that displays different types of vapes on a company website.
var menu = [["Large Vapes", 20.99], ["Disposable Vape", 9.50], ["Strawberry Vape", 12.99]];While this array is useful and innocent, this design has many downsides including:
- Search – If we search this array, the time take will be O(N) (slow)
- Insertion – If we insert, the time will take will also take O(N) (slow)
O(N) runtime is not exactly the worst, but a Dictionary could greatly improve the runtime speed.
By creating a Dictionary<>, it has an amazing super power and that’s fast reading.
Dictionary<string, double> menu = new Dictionary<string, double>
{
{ "Large Vapes", 20.99 },
{ "Disposable Vape", 9.50 },
{ "Strawberry Vape", 12.99 },
};A hash table is a list of pair values. The first item in each pair is called the key, and the second item is called the value. In a dictionary, the key and value have significant meaning.
In our example, the string "Large Vapes" is the key, and 20.99 is the value. This indicates that to purchase a large vape is $20.99.
In C#, we can lookup values in a dictionary using brackets:
menup["Large Vapes"];Why Are Dictionaries So Fast? Hashing Explained
Do you remember making secret codes as a kid and trying to have your friends decipher messages?
For example, imagine a simple way to map letters to numbers:
A = 1
B = 2
C = 3
D = 4
According to this code,
CAB converts to 312
This process of taking characters and converting them to numbers is know as hashing. The code we use to make these numbers is called a hash function.
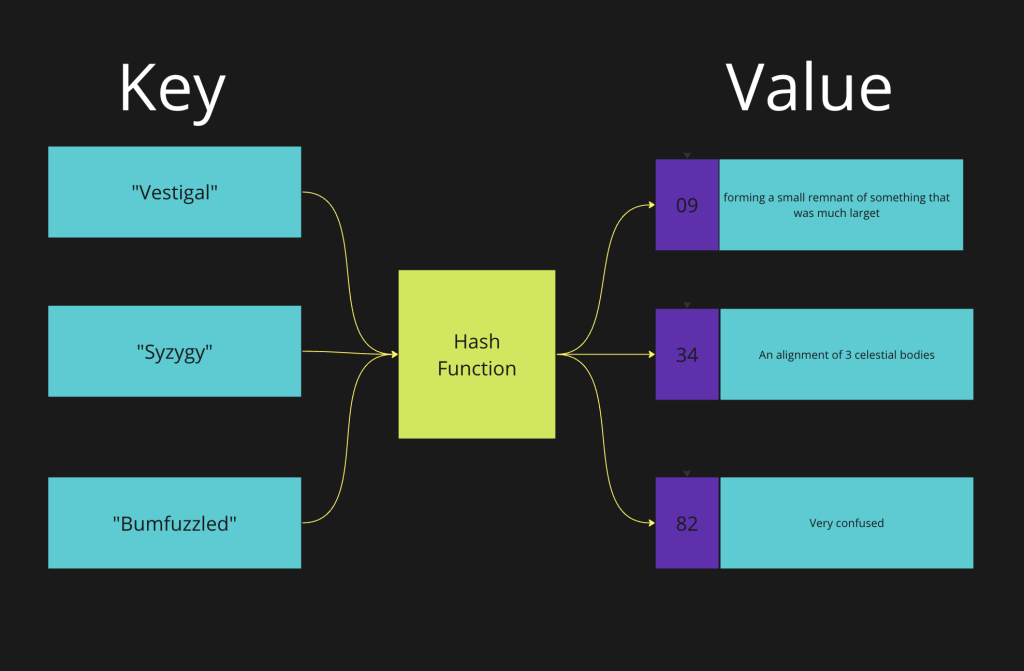
When we insert or search for data in a Dictionary<> the computer does the following steps:
- The computer places the key you provided into a hash function.
- Once the hash function is computed it places the “secret code” in a bucket.
- That bucket is used to identify the value.
Because the key determines the placement of the value, we use this principle to make lookups blazingly fast. We can now understand why a dictionary would yield faster lookups for our vape store menu. With an array we loop up every single piece of data, however, we can now use keys allows us to search in constant time.
Checking Existence In Strings (LeetCode Hack #1)
One of the most common applications of a Dictionary<> is LeetCode. You will often be given questions to ask where something exists. Since an array needs O(n) to do this using a Dictionary<> can great improve the time complexity.
The following is an easy LeetCode questions that asks us to search an array and find the two elements that add up to a specified target.
Given an array of integers
Two Sum – LeetCodenumsand an integertarget, return indices of two numbers such that they add up totarget. You cannot use the same index twice.
The brute force of the solution would be to use a nested loop to iterate over every pair of indices and check if the sum is equal to target.
public int[] TwoSum(int[] nums, int target) {
for(int i = 0; i < nums.Length; i++)
{
for(int j = i + 1; j < nums.Length; j++)
{
if(nums[j] == target - nums[i])
{
return new int[] { i, j };
}
}
}
return null;
}For each element in the array, we try to find its complement by looping through the rest of the array which takes O(n) time. Therefore, the time complexity is O(n^2).
To improve our runtime complexity, we need a more efficient way to check if the complement exists in the array. What is the best way to maintain a mapping of each element in the array? A dictionary.
We can reduce the loop time from O(n) to O(1) by trading space for speed.
public int[] TwoSum(int[] nums, int target)
{
Dictionary<int, int> dict = new Dictionary<int, int>();
for (int i = 0; i < nums.Length; i++)
{
int complement = target - nums[i];
if (dict.ContainsKey(complement))
{
return new int[] { dict[complement], i };
}
dict.Add(nums[i], i);
}
throw new ArgumentException("No two sum solution");
}Check Existence In Arrays (LeetCode Hack #2)
Let’s say we need to determine whether one array is a subset of another array.
["a", "b", "c", "d"]
["b", "c"]The second array, [“b”, “c”] is a subset of the first array, because the values are contained within the first array.
How could we write a function that checks whether one array is a subset of another?
One way we could do this is by using nested loops. We can iterate through every element of the smaller array, and for each element in the smaller array, we’d iterate through each element in the larger array.
If we never find an element in the smaller array that isn’t contained within the larger array, our function return false.
static bool IsSubset(int[] smallArr, int[] largeArr)
{
for (int i = 0; i smallArr.Length; i++)
{
bool foundMatch = false;
for (int j = 0; j < largeArr.Length; j++)
{
if (smallArr[i] == largeArr[j])
{
foundMatch = true;
break;
}
}
if (!foundMatch)
{
return false;
}
}
return true;
}When we analyze the efficiency of this algorithm, we find that it’s O(N * M), since it runs for the number of items in the first array multiplied by the number of items in the second array.
Let’s do away with this nasty, nested loop and replace it with a dictionary.
In our new approach, after we’re going to run a single loop through the larger array, and store each value in a dictionary.
Dictionary<char, bool> dict = new();
foreach(var value in largeArr)
{
dict[value] = true;
}
{ "a": true, "b": true, "d": true }In this code, we create a new dictionary inside the dict variable. After that, we iterate through each value in the largerArr, and add the item from the array to the dictionary. This becomes our index that will allow us to conduct O(1) lookups on these items.
Here is where things get good. Once the loop finishes we can use this dictionary almost as a “memory card” to check the values previously stored. Instead of iterating over each variable we can check the previous values stored.
foreach(var value of smallerArray)
{
if(!dict.ContainsKey(value) { return false };
}This iterates each item in the smallerArray and checks to see whether it exists as a key inside the dictionary. The dictionary stores all the items from the previous largerArray, so not finding inside the larger means it does not exist.
Let’s put all these concepts together:
static bool IsSubset(int[] largeArr, int[] smallArr)
{
Dictionary<int, bool> dict = new();
foreach (var value in largeArr)
{
dict[value] = true;
}
foreach (var value in smallArr)
{
if (!dict.ContainsKey(value))
{
return false;
}
}
return true;
}We just drastically reduced the number of steps taken to complete this algorithm. We iterated through each item of the larger array once to build the hash table.
Instead of iterating through the array and searching each element over and over, we can simply put a simple lookup inside our for loop.
Conclusion
Dictionaries are powerful when it comes to fast code that works with large amounts of data. With their O(1) lookups they are almost impossible to beat in many situations and they are one of the most popular data structures in LeetCode style questions.