To truly optimize SQL queries, it’s essential to understand the underlying data structures in SQL Server. The way data is organized and accessed directly impacts query performance. Without a solid grasp of these internal structures, it’s difficult to interpret query execution plans or comprehend the access methods SQL Server uses. Learning about these structures will help you make informed decisions about indexing, access paths, and how to efficiently retrieve data. By mastering data structures, you’ll be better equipped to measure and improve query performance, enabling you to tackle complex tuning tasks more effectively.
Pages: The Basic Storage Unit
In SQL Server, the fundamental unit of data storage is called a page, which is 8 KB in size. For traditional disk-based tables, this is the smallest amount of data SQL Server can read or write at one time.

Each page has a 96-byte header that stores essential metadata, such as:
• The allocation unit it belongs to.
• Pointers to other pages (useful for indexes).
• Information about how much free space remains on the page.
The rest of the page stores the actual data records or index entries. At the end of the page, there’s a row-offset array, which helps SQL Server quickly locate specific rows within the page.
Extents
In SQL Server, data is stored in units called extents, which consist of eight 8-KB pages (64 KB total). These extents are crucial for managing how space is allocated for tables, indexes, and other database objects. SQL Server uses two types of extents to balance efficiency and performance: mixed extents and uniform extents.

- Mixed Extent – When a new object (like a table or index) is created, SQL Server initially assigns space one page at a time from mixed extents. These extents can store pages from multiple different objects, ensuring that smaller objects don’t waste space.
- Uniform Extents – Once an object grows to eight pages, SQL Server switches to using uniform extents, where all pages belong to the same object. This improves performance as data for the object is stored together.
Tables
In SQL Server, tables can be organized in one of two ways: heap or B-tree. The difference between these two types lies in how the data is stored and indexed, which can impact performance and how data is accessed.
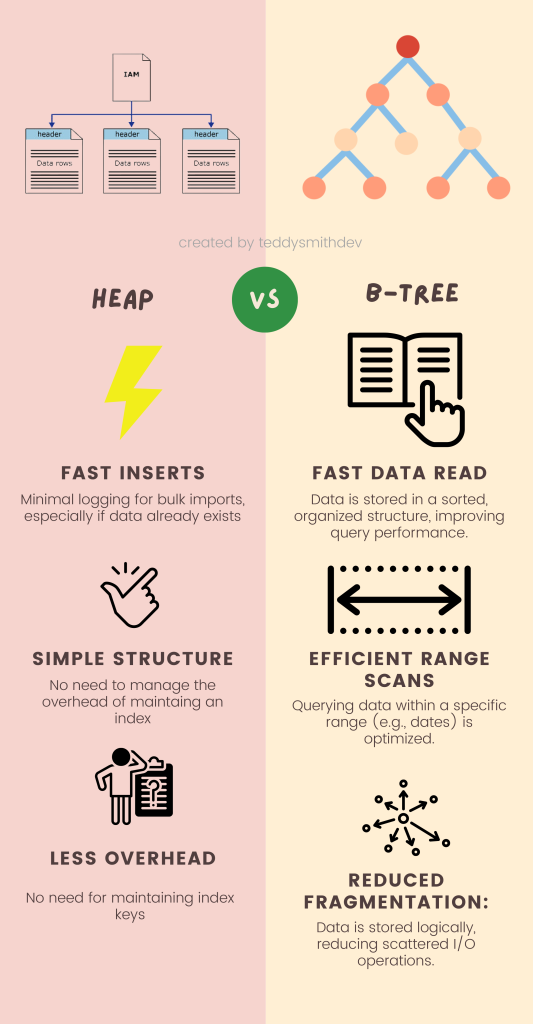
What is a Heap in SQL Server?
A heap is a table without a clustered index, meaning the data is stored without any particular order. Think of it like a pile of papers placed wherever there’s space.
To keep track of where the data is stored, SQL Server uses Index Allocation Maps (IAMs), which help locate the pages containing the data. As the table grows, multiple IAMs may be needed to manage the data efficiently. When SQL Server scans a heap, it uses these IAMs to figure out where to read the data, usually doing so in a way that maximizes efficiency.
When new data is added to a heap, SQL Server looks for space on existing pages using Page Free Space (PFS) pages. If there isn’t enough space, a new page is created to store the data.
For updates, if a row gets too big for its original page, SQL Server moves it to a new page and leaves behind a forwarding pointer to direct future searches to the updated row.
In summary, heaps are an unordered way to store data, offering flexibility and simplicity, especially when indexing isn’t needed. They are ideal for scenarios where data doesn’t need to be retrieved in a specific order.
What Is A B-Tree in SQL Server?
In SQL Server, all indexes for tables stored on disk are organized in a special structure called a B-tree. A B-tree is a balanced tree, meaning that the data is evenly distributed to make searching and accessing information efficient.
A clustered index uses this B-tree structure, but it’s important to note that the clustered index actually contains the entire table’s data. The leaf level of the B-tree holds the table’s data rows, organized based on the column(s) you’ve chosen as the index key (such as a date column). So, when you query the data, SQL Server can quickly find and retrieve it using this structure.
In simple terms, a clustered index organizes your table’s data in a sorted, balanced structure to help speed up data retrieval.
Non-Clustered Index
A nonclustered index in SQL Server is similar to a clustered index, but with a key difference: it doesn’t contain the actual data. Instead, it stores the indexed columns and a pointer to the data row, known as a row locator.
• When the table is organized as a heap (no clustered index), the row locator is a physical pointer called a RID (Row Identifier), which tells SQL Server exactly where the data row is located.
• When the table has a clustered index (B-tree), the row locator is a clustering key, which is a logical pointer to the data row, making it more efficient when rows are moved around due to updates or inserts.
In both cases, SQL Server uses these row locators to find the actual data when a query is run. However, looking up many rows using a nonclustered index can be more expensive in terms of performance, especially with a heap since it involves more page reads. On a clustered index, SQL Server uses a key lookup to find the data more efficiently.
Conclusion
Understanding the internal data structures of SQL Server, such as heaps, B-trees, and indexes, is crucial for optimizing database performance and efficiency. These structures determine how data is stored, retrieved, and managed, directly affecting query speed, resource usage, and overall system performance. By knowing how SQL Server organizes and accesses data, you can make informed decisions about indexing strategies, query optimization, and storage management, leading to faster data retrieval, reduced fragmentation, and improved scalability. Mastering these concepts empowers database administrators and developers to fine-tune their systems for peak performance and reliability.